
2020-10-20
Column
・論文著者:Walid Krichene (google research) & Steffen Rendle (google research)
Rendleさんは皆さんご存知のFactorization MachinesやBayesian Personalized Rankingを作った方です。
・学会:KDD2020
・論文リンク:https://dl.acm.org/doi/pdf/10.1145/3394486.3403226
・必要な基礎知識: ランキング学習や推薦における評価指標 (DCGやRecallなど)
・参考: https://blog.brainpad.co.jp/entry/2017/08/25/140000
半熟仮想株式会社 共同創業者兼科学統括および東京工業大学 工学院経営工学系 学士課程4年の齋藤です。普段は、反実仮想機械学習の理論と応用をつなぐような研究をしています。反実仮想機械学習に関しては、拙著のサーベイ記事をご覧ください。
ランキング学習や推薦モデルの性能評価には、Recallなどのランキング評価指標が用いられますが、これらの指標を計算する際にネガティブサンプリングを用いてしまうと、誤った評価を得る危険性があることを理論・実験的に示したという論文です。
あまりたくさん論文を書かない(が多大なインパクトを残している)Rendleさんが論文を書いたということで、これは読まねばと思ったため。
Rendleさんのgoogle scholar: https://scholar.google.com/citations?user=yR-ugIoAAAAJ&hl=ja
多くの推薦システムに関する論文や実応用の場面では、推薦モデルのランキング性能の評価の際にネガティブサンプリングが用いられます。理想的には、あるモデルの評価をする際に、そのモデルの出力のをもとに、ときには数千万~数億個存在するアイテムに順位をつけ、その順位をもとにDCGやRecallなどのランキング評価指標を計算します。この計算をこれまた数千万~数億人存在するユーザーごとに計算し、平均をとることでモデルのランキング性能を評価します。
しかし、アイテム数が膨大にあるとこのような計算をしていられないこととが多いため、計算量を落とす方法としてネガティブサンプリングが登場します。例えば、各ユーザーごとにランキング評価指標を計算する際に、1万個だけのネガティブサンプル(クリックが発生しなかったアイテムなど)とそれ以外のポジティブサンプルのみをモデルによって並べ替えることにより、ランキング性能を素早く評価しようという算段です。これは多くの推薦研究の実験パートで用いられているランキング性能の評価方法であり、実務場面でも使われることがある評価方法だと思います。
さて本論文の主張は「AUC以外のランキング評価指標を用いて推薦モデルのランキング性能を評価する際には、ネガティブサプリングを用いるべきではない」というものです。
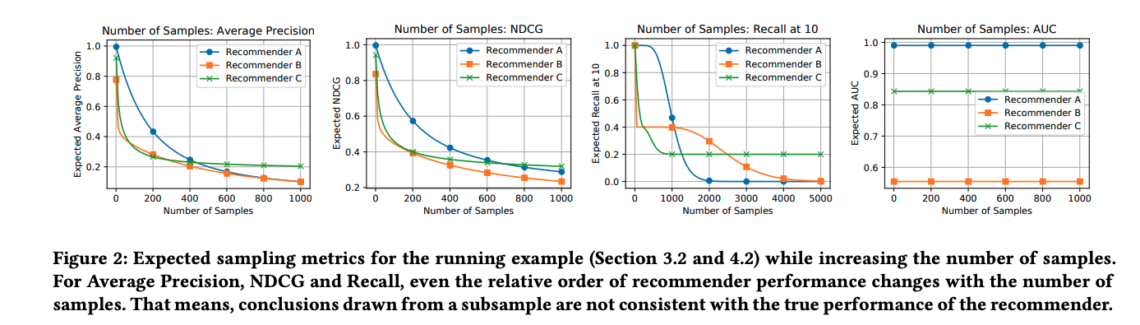
左からAverage Precision・NDCG・Recall@10・AUCを用いた時の結果が並んでいます。それぞれのfigureの横軸は評価に用いるネガティブサンプルの数を表しています。図を見てみると分かる通り、Average Precision・NDCG・Recall@10を用いる際には、ネガティブサンプルの数に依存して推薦モデルA(青線)・B(オレンジ線)・C(緑線)の性能の順番が変化していることがわかります。すなわち、ネガティブサンプリングを用いると誤ったモデル選択につながってしまう可能性があるのです。一方で、AUCに関しては推薦モデルA・B・Cの性能の順番がネガティブサンプルの数に非依存であることがわかります。
さてここでは理解しやすい数値実験の結果を取り上げましたが、論文の4章では、簡易な数式を用いてネガティブサンプリングが評価に悪影響を及ぼしてしまうメカニズムを説明しています。また5章では、ネガティブサンプリングを使わざるを得ない場合のランキング性能評価の補正方法を紹介しています。最後に6章では、実データを用いた実験を行っています。もしネガティブサンプリングを実務で使っているという方がいたら、この辺りの詳細を含めて本論文を読んでみると良いでしょう。
多くの論文が標準的に採用している手法の性能評価方法に疑問を呈したという意味で、インパクトの大きい論文だと感じました。Rendleさんの他の論文と同様に、推薦システムを勉強する人が、必ず読むべき論文になっていきそうな雰囲気がプンプンします。また一つの強力な主張を、簡単な数式や複数の具体例を用いながらわかりやすく説得力のある形で記述しており、論文の書き方的な視点でも参考になります。このような論文を読むと論文の数ではなく納得の一作を書くことに集中したいと思わされます。
推薦施策のオフライン評価がオンライン評価と合わないのは大きく2つの理由があります。
(i) ネガティブサンプリングを用いて定義とは異なる計算をしている (本記事の内容)
(ii) ポジションバイアスや過去の推薦方策などによるバイアスの影響を無視している
それぞれの点に着目した論文が、最近いくつか出てきているので、以下にまとめました。
(i) ネガティブサンプリング
On Sampling Top-K Recommendation Evaluation (KDD2020)
同じくKDD2020に採択された本記事で紹介した論文の後続研究
(ii) バイアス
Unbiased Offline Recommender Evaluation for Missing-Not-At-Random Implicit Feedback (RecSys2018)
clickなどのimplicit feedbackに基づいてDCGやRecallなどのランキング評価指標でオフライン評価する場合のバイアス除去方法を提案
Doubly Robust Estimator for Ranking Metrics with Post-Click Conversions (RecSys2020)
拙著論文。click -> conversionなど実ECサイトなどでよくみられる2段階feedbackの場面でDCGやRecallなどのランキング評価指標でオフライン評価する場合のバイアス除去方法を提案
Offline Evaluation of Ranking Policies with Click Models (KDD2018)
複数のアイテムを推薦する場合に、推薦リスト内のクリック数(などの目的変数)の和をオフライン評価する方法を議論
以下問い合わせフォームよりお願いします